
Global brands, SMEs, and startups need cloud-based big data solutions to support growth and maximize the efficiency of operations like marketing, product positioning, and logistics. However, running big data analytics on-premise is costly.
Cloud computing greatly reduces the cost of big data analytics, but moving to the cloud or building analytics solutions there from scratch can be challenging.
If you’re facing this dilemma, read on. We’re sharing the peculiarities of moving to or building cloud-based big data platforms, how to overcome the inherent challenges, and best practices for planning, building, and running big data platforms in the cloud.
The big data analytics landscape in 2023
According to a McKinsey report, cloud-based big data solutions can bring 7–15% EBITDA growth, cut IT expenses by 10–20%, and increase the speed of product development by up to 30%. Another study by McKinsey & Company found that organizations that use big data and analytics effectively are up to 23 times more likely to acquire customers, up to 9 times more likely to retain those customers, and up to 26 times more likely to be profitable than their peers.
Also, Forbes Insights found that organizations that use big data analytics for decision-making are more likely to report revenue growth of 10% or more compared to their peers.
These are reasons enough to invest heavily into big data analytics. But the current economic downturn has led businesses worldwide to cut costs.
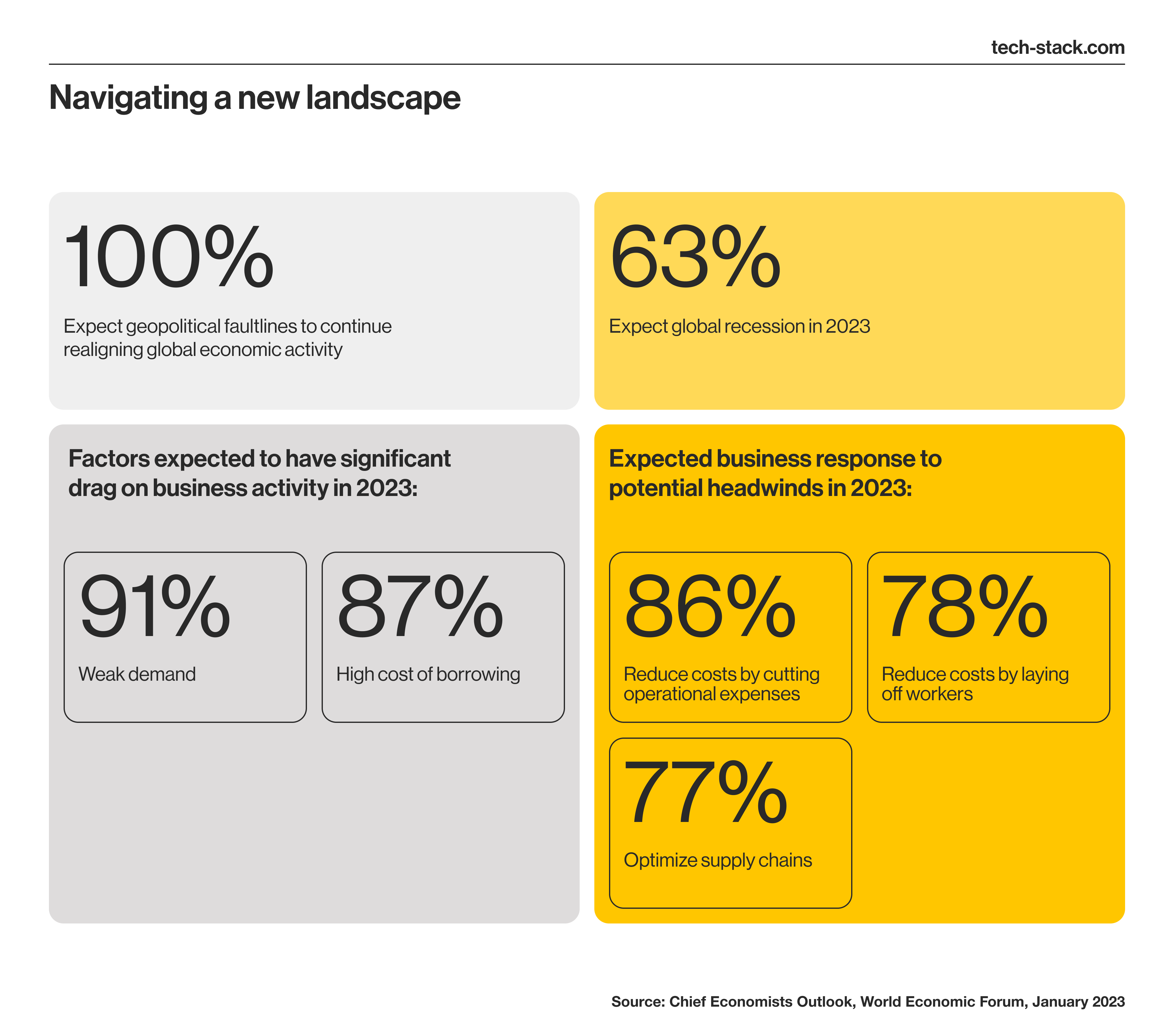
According to the 2023 World Economic Forum outlook, 86% of businesses plan to cut operational expenses, 78% will lay off workers, and 77% want to optimize their supply chains in 2023. Businesses may also need to reduce costs related to big data analytics.
Transitioning to the cloud may be the answer for companies that want to ensure the success of their big data initiatives and remain competitive through the recession.
A successful transition to the cloud requires businesses to get a lot of things right, starting with selecting the best cloud-deployment architecture. Let’s briefly go over the available options.
Types of Architecture for Cloud-Based Data Solutions
The types of cloud deployment for big data platforms you can choose from are the following:
- Centralized architecture
- Decentralized architecture
- Hybrid architecture
- Serverless architecture
- Event-driven architecture
The choice of cloud architecture depends on your business needs. Here are the main features of each type.
Centralized data architecture
With centralized big data architecture, incoming data nuggets from every separate domain/subject (financial data, social media, payroll numbers, etc.) are stored under one storage account in a data lake or data warehouse. This way, data from multiple domains is combined to form a holistic view of your business, ensuring centralized ownership of that data (assigned executives and/or IT department).
While easier to analyze, this approach requires immense data processing and storage resources. As an alternative, you might go for decentralized (federated) big data architecture.
Decentralized big data architecture
With this approach, the data from separate subjects/domains is not copied into a central data lake/warehouse. Instead, it is stored in separate data lakes available from under one storage account. This enables distributed ownership of the data and reduces the ETL data pipeline, while also speeding up time-to-value.
But it comes with certain trade-offs:
- absence of data versioning due to no singular data view
- slower system performance as compared to a centralized one
- disruption at data sources break the chain of operations
That’s why you may want to opt for a combination of the two mentioned types, called a hybrid big data architecture.
Hybrid big data architecture
Under this model, you combine a centralized data warehouse with structured data, and federated data lakes with unstructured data. Hybrid data lakes can serve as sources for training ML models or performing data science tasks. Otherwise, this data can go through standard ETL pipeline to become structured data in a data warehouse and be used for business intelligence and analytics.
However, all these approaches require immense resources to be on standby, while data sources might not produce data at stable speed or volumes. This means these resources might be idle for a long time, which is far from optimal. Resource conservation concerns call for serverless architecture.
Serverless big data architecture
Serverless data lakes are able to ingest data from any source, in batches or streams. Data storage is also available at scale to support storing multiple years’ worth of data and scaling up and down on request.
Such solutions are mainly provided by serverless computing providers, like AWS. AWS Glue handles batch data processing, while AWS Firehose, Kinesis, and Lambda support both batch and streaming data ingestion. Storage for such data lakes can be built on AWS, Google, Azure or other public cloud platforms to ensure scalability and cost-efficiency of deployment.
However, even running the absolute minimum resources on standby might not be optimal for certain tasks. Sometimes, data extraction and transformation speed can be sacrificed to minimize idle resource spending. Event-driven data architectures help achieve this goal.
Event-driven data architecture
Unlike batch processing or data stream ingestion, event-driven big data architectures spin up the required infrastructure only once the event occurs. These event triggers can be API calls, online purchases on e-commerce websites, webhooks, or any other types of events. Once a trigger takes place, decoupled services combine into a data architecture needed to process the data acquired—and then are shut down to conserve resources.
Apache Kafka, Confluent, or Cloudkarafka are tools enabling you to build event-driven big data architectures and leverage minute-to-minute data analytics without spending a fortune on idling resources. These solutions can run on Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, IBM Cloud, Oracle Cloud, Alibaba Cloud, Snowflake, Cloudera, Databricks, and Hortonworks.
All the above cloud platforms can easily scale your infrastructure depending on workload, store and process enormous datasets, and enable real-time analytics through AI-powered tools. However, cloud-based big data solutions provide quite a lot of other benefits too.
Benefits of Cloud-Based Big Data Solutions
Many industries, like banking, healthcare, media, entertainment, education, and manufacturing, have achieved significant results by moving their big data workloads to the cloud.
In 2022, Netflix moved all its infrastructure to Amazon’s cloud. Twitter migrated its ad analytics platform to Google Cloud right before the COVID-19 pandemic struck, and it can now roll out new features and updates to its analytics platform significantly faster. Amazon Prime relies on its big data analytics engine and AI algorithms to provide personalized recommendations for videos, music, and Kindle books to its customers worldwide.
Businesses sometimes favor different cloud-based big data solution providers depending on the business’s industry:
- StreamBase Systems, 1010data, NICE Actimize, Altair Panopticon, and Quartet FS for banking
- Splunk, InfoChimps, Visible Measures, and Pervasive Software for entertainment, media, and communication businesses
- Humedica and IBM Explorys for Healthcare
- AWS, Google Cloud, and Microsoft Azure as general practice service and infrastructure providers for big data analytics
These and other big data tools offer the scalability, cost-efficiency, data agility, flexibility, security, innovation and resilience businesses need.
Let’s delve deeper into each of these benefits.
Scalability
Whether running big data solutions in a public, private, or hybrid cloud, you can set a schedule to spin cloud instances up or down if you expect regular changes in data ingestion pipeline requirements. Alternatively, you can have your big data infrastructure automatically scale up and down depending on the current resource load. This ensures your analytical solution is able to handle any volumes of data your business goals might require.
Cost efficiency
With precise resource allocation, failover scenarios, and data workload balancing, you’ll never waste money on unneeded cloud resources. Scaling up and down on demand requires a lot of automation, set workload thresholds, and automated triggers like webhooks, API calls, and other tools. However, this can ensure your infrastructure is cost-efficient and scales down as soon as the demand spike is over, so you don't overpay for idling instances.
Data agility
With big data, it’s imperative to process incoming raw data as soon as possible to gain meaningful insights. This agility ensures your big data platform can handle any workloads quickly, reliably, at the needed scale, and regardless of the underlying data infrastructure.
Flexibility
Big data solutions are flexible since they can grow or shrink and adjust to meet revised sets of analytics requirements. Data flexibility also means the analytics results are influenced not only by the conditions and variables of data ingestion but also by how the data is transformed prior to processing. Change is prevalent in data sources, so data analytics solutions must be able to cope.
Accessibility
Data can be ingested from a variety of sources, but it will remain unsorted, in obscure formats, with wrong headers and column types, with unpredictable encoding, and more. Accessibility means the data is structured, normalized, cleared of duplicates, transformed and packaged into a transparent schema, easing its further analytics and, therefore, increasing its value. Cloud deployment ensures you always have sufficient resources to perform analytics in real-time.
Security
Big data security in the cloud stands as an umbrella term for the whole set of tools and practices used to prevent unauthorized data access, theft, misuse, and forgery. Due to the complex nature of cloud-based big data infrastructure, federated data input sources, and multistage ETL pipelines, these measures should cover threat both from outside and inside the organization.
Cloud-based big data solutions, therefore, call for comprehensive multi-faceted cybersecurity measures but deploying them can significantly decrease general cyber threat perimeter and surface for your organization.
Innovation
When coupled with AI algorithms and ML models, cloud-based big data analytics enables companies to uncover hidden patterns that would otherwise go unnoticed in their data flow. These discoveries can lead to improving operational efficiency, enabling new revenue streams or supporting innovation to provide better, more value-adding services. Cloud-based big data analytics is one of the most potent growth drivers for innovation and competitiveness.
Resilience
Despite best efforts, outages caused by human mistakes, cybersecurity lapses, or equipment failures still happen. Big data cloud deployments can recover infrastructure within milliseconds to ensure the continuity of your workflows and data analytics processes.
These benefits sound great, but you can only achieve them if you implement big data solutions correctly. Below, we list some best practices we use at Techstack to provide a stable architecture so that you can reap all the benefits of cloud-based big data tools.
Challenges of Cloud-Based Big Data Solutions
The core challenges for big data processing include ensuring data security and compliance, building transparent data management, and streamlining integration with various tools.
Data security and compliance concerns
Cloud-based big data analytics platforms with multiple data entry points call for watertight security measures. Gathering, accessing, processing, and storing personal data like social media posts and any other PII (personally identifiable information) requires following strict security protocols. For example, HIPAA has rules for managing electronic health records (EHRs), medical imaging, and research results.
Use your cloud platform’s security features to the fullest and implement additional measures if needed. Cloud computing can shift liability from you to the service provider in some cases, but selecting the appropriate data formats and handling them securely remains your responsibility.
Data management challenges
Your big data solution might gather unstructured data, often incomplete and impossible to validate. Therefore, incorporate mechanisms for data validation and correction (e.g., updating databases, repairing data sources, and using reliable data gathering agent authentication methods). The output of data validation procedures is structured data ready for use in business intelligence tools, like analytics and training machine learning models.
To meet GDPR requirements, implement data access and update procedures, automated deprecation, export, and removal upon request. Role-based access control (RBAC) and user management policies help ensure that only authorized users can access the data you process within your analytics processes.
Integration challenges
Your big data solution must retrieve data from multiple sources in various formats (e.g., social media posts, website sessions, product usage logs, or reviews). Standardization of this data (transforming various data types into a single format that can be used by ML/AI algorithms) requires streamlined and transparent integration with your data sources. The integration with the rest of your software toolkit (e.g., customer relationship management software (CRM), marketing engagement platforms, historical data storages, and more) is essential as well.
If you use machine learning (ML) models and software for predictive and prescriptive analytics like Hadoop, Spark, R Software, and NoSQL databases, you’ll need reliable and predictable ways for them to interact with your big data analytics platform. Although most analytics tools have in-depth developer documentation to help you integrate third-party libraries, correct implementation still remains challenging.
Best Practices for Implementing Cloud- Based Big Data Solutions
By following these practices, you can ensure that your cloud-based big data infrastructure is effective, efficient, and enabling you to gain valuable insights from your data and make informed business decisions.
Download Now
Conclusion
The oncoming recession requires businesses to optimize their operational efficiency. Running big data analytics is essential to achieving these goals. But it comes with several challenges to overcome, from data security and dynamic infrastructure scaling to integration with third-party software.
Cloud deployment facilitates cost efficiency, scalability, data processing agility, flexibility, and operational resilience. However, to enable seamless implementation and reap these benefits, you should plan, design, and execute migration to the cloud using industry best practices.
Techstack is a technology partner with a proven record of successful software development. We can help with cloud migration or build a big data analytics platform from scratch using the CSP of your choice. Due to our extensive expertise in big data analytics development, we can assist you at every stage of your cloud transition.
Contact us with your requirements, and let’s take your business to the cloud!




